▍Monitoring Stack¶
Настройка мониторинга на Prometheus + Cadvisor + Node Exporter + Grafana + Alertmanager в Docker Swarm¶
Ранее мы уже настраивали эту систему мониторинга, но на одном сервере. Теперь же можно её развернуть в кластере Docker Swarm.
Вводная часть¶
| hostname | ip | role |
|---|---|---|
| 192.168.0.5 | srv-mainframe | worker |
| 192.168.0.10 | srv-nas | worker |
| 192.168.0.20 | srv-k8s | manager |
В качестве распределенного хранилища будет использоваться Ceph.
Compose для нашего стека мониторинга¶
version: '3.9'
services:
########################### MONITORING
grafana:
image: grafana/grafana-oss:latest
volumes:
- /docker/conf/grafana:/var/lib/grafana
- /etc/localtime:/etc/localtime:ro
networks:
- traefik-public
deploy:
replicas: 1
restart_policy:
condition: on-failure
update_config:
parallelism: 1
monitor: 60s
failure_action: rollback
order: start-first
placement:
constraints: [node.hostname == srv-k8s]
labels:
- "traefik.enable=true"
- "traefik.http.routers.grafana.tls=true"
- "traefik.http.routers.grafana.rule=Host(`grafana.example.ru`)"
- "traefik.http.routers.grafana.middlewares=WhitelistHome"
- "traefik.http.services.grafana.loadbalancer.server.port=3000"
prometheus:
image: prom/prometheus
command:
- '--config.file=/etc/prometheus/prometheus.yml'
- '--storage.tsdb.path=/prometheus'
- '--storage.tsdb.retention=750h' # автоочистка данных старше месяца
- '--web.console.libraries=/usr/share/prometheus/console_libraries'
- '--web.console.templates=/usr/share/prometheus/consoles'
depends_on:
- cadvisor
volumes:
- /etc/localtime:/etc/localtime:ro
- /docker/conf/prometheus:/prometheus
- /var/run/docker.sock:/var/run/docker.sock:ro
networks:
- traefik-public
deploy:
replicas: 1
restart_policy:
condition: on-failure
update_config:
parallelism: 1
monitor: 60s
failure_action: rollback
order: start-first
placement:
constraints: [node.hostname == srv-k8s]
labels:
- "traefik.enable=true"
- "traefik.http.routers.prometheus.rule=Host(`prometheus.example.ru`)"
- "traefik.http.routers.prometheus.entrypoints=https"
- "traefik.http.routers.prometheus.tls=true"
- "traefik.http.routers.prometheus.middlewares=WhitelistHome"
- "traefik.http.services.prometheus.loadbalancer.server.port=9090"
alertmanager:
image: prom/alertmanager
environment:
- SMTP_SERVER=smtp.mail.ru:465
- [email protected]
- [email protected]
- [email protected]
- SMTP_AUTH_PASSWORD=password
volumes:
- /etc/localtime:/etc/localtime:ro
networks:
- traefik-public
deploy:
replicas: 1
restart_policy:
condition: on-failure
update_config:
parallelism: 1
monitor: 60s
failure_action: rollback
order: start-first
placement:
constraints: [node.hostname == srv-k8s]
node-exporter:
image: prom/node-exporter
volumes:
- /proc:/host/proc:ro
- /sys:/host/sys:ro
- /:/host:ro,rslave
command:
- '--path.rootfs=/host'
- '--path.procfs=/host/proc'
- '--path.sysfs=/host/sys'
- --collector.filesystem.mount-points-exclude
- "^/(sys|proc|dev|host|etc|rootfs/var/lib/docker/containers|rootfs/var/lib/docker/overlay2|rootfs/run/docker/netns|rootfs/var/lib/docker/aufs)($$|/)"
networks:
- traefik-public
deploy:
mode: global
resources:
limits:
memory: 128M
reservations:
memory: 64M
restart_policy:
condition: on-failure
update_config:
parallelism: 1
monitor: 60s
failure_action: rollback
order: start-first
labels:
- prometheus-job=node-exporter
- prometheus-port=9100
cadvisor:
image: gcr.io/cadvisor/cadvisor
command:
- --docker_only
volumes:
- /var/run/docker.sock:/var/run/docker.sock:ro
- /:/rootfs:ro
- /var/run:/var/run:rw
- /sys:/sys:ro
- /var/lib/docker/:/var/lib/docker:ro
networks:
- traefik-public
deploy:
mode: global
restart_policy:
condition: on-failure
update_config:
parallelism: 1
monitor: 60s
failure_action: rollback
order: start-first
labels:
- "prometheus-job=cadvisor"
- "prometheus-port=8080"
networks:
traefik-public:
external: true
Настройка Prometheus¶
Создадим директорию /docker/conf/prometheus в которой добавим следующие файлы:
Конфиг prometheus¶
# Docker Swarm.
# my global config
global:
scrape_interval: 15s # Set the scrape interval to every 15 seconds. Default is every 1 minute.
evaluation_interval: 15s # Evaluate rules every 15 seconds. The default is every 1 minute.
# scrape_timeout is set to the global default (10s).
# Alertmanager configuration
alerting:
alertmanagers:
- static_configs:
- targets: ['alertmanager:9093']
# Load rules once and periodically evaluate them according to the global 'evaluation_interval'.
rule_files:
- "node_down.yml"
# - "first_rules.yml"
# - "second_rules.yml"
scrape_configs:
# Make Prometheus scrape itself for metrics.
- job_name: "prometheus"
static_configs:
- targets: ["localhost:9090"]
- job_name: 'docker'
dockerswarm_sd_configs:
- host: unix:///var/run/docker.sock
role: nodes
relabel_configs:
- source_labels: [__meta_dockerswarm_node_address]
target_label: __address__
replacement: $1:9323
- source_labels: [__meta_dockerswarm_node_hostname]
target_label: instance
- job_name: "dockerswarm"
dockerswarm_sd_configs:
- host: unix:///var/run/docker.sock # You can also use http/https to connect to the Docker daemon.
role: tasks
relabel_configs:
# Only keep containers that should be running.
- source_labels: [__meta_dockerswarm_task_desired_state]
regex: running
action: keep
# Only keep containers that have a `prometheus-job` label.
- source_labels: [__meta_dockerswarm_service_label_prometheus_job]
regex: .+
action: keep
# Use the prometheus-job Swarm label as Prometheus job label.
- source_labels: [__meta_dockerswarm_service_label_prometheus_job]
target_label: job
# Это правило нужно, чтобы эндпоинты формировались из меток prometheus-job и prometheus-port
- source_labels: [__address__, __meta_dockerswarm_service_label_prometheus_port]
separator: ';'
regex: (.*):(.*);(.*)
replacement: ${1}:${3}
target_label: __address__
# Это правило больше для красоты, чтобы в качестве хостов были не рандомные IP 10.0.2.173:8080 которые меняются у контейнеров, а hostname серверов srv-nas:8080 на которых они запущены.
- source_labels: [__meta_dockerswarm_node_hostname, __meta_dockerswarm_service_label_prometheus_port]
separator: ';'
regex: (.*);(.*)
replacement: ${1}:${2}
target_label: instance
При данном конфиге джобы у нас будут автоматически формироваться, т.е. ранее нужно было указывать:
то теперь эти данные берутся из меток:
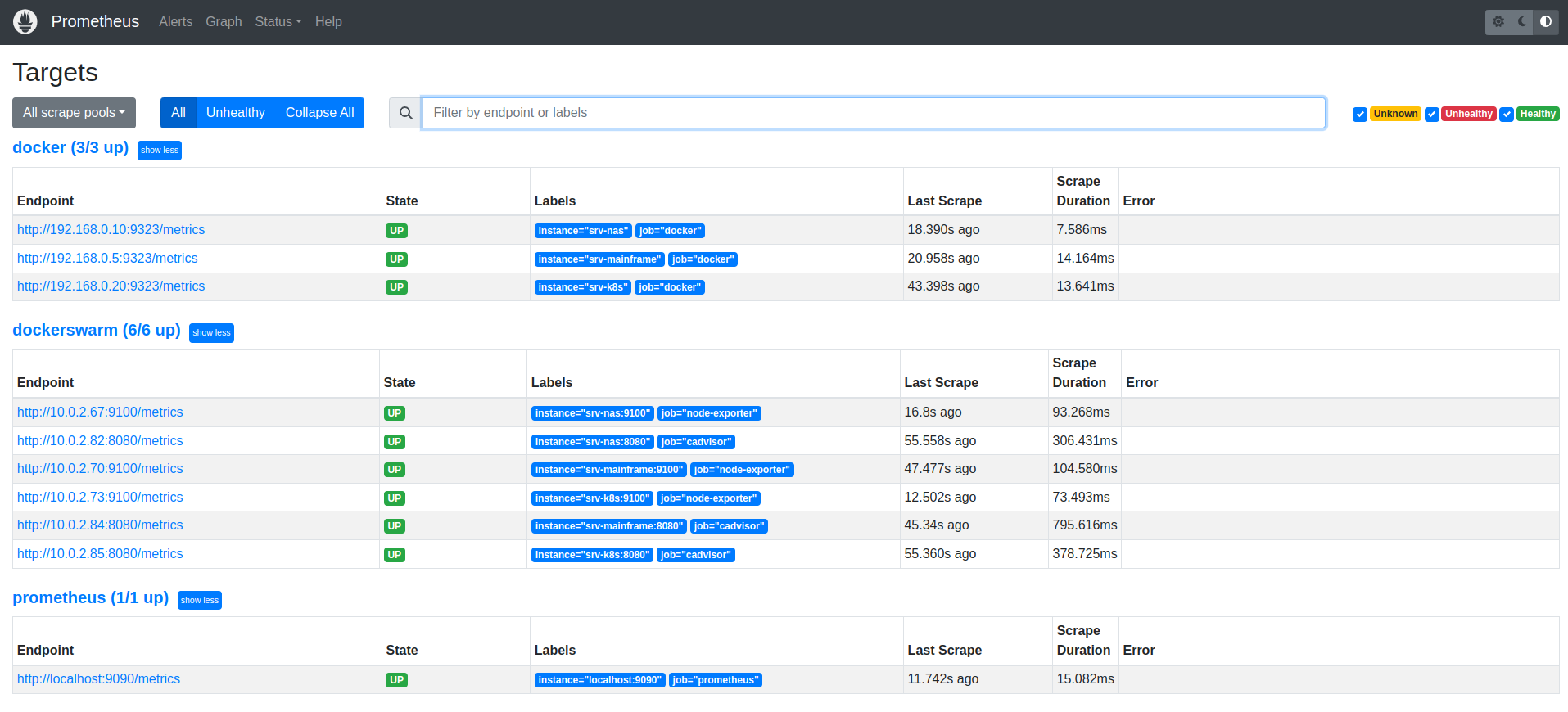
и исходя уже из них идёт формирование адреса сервиса таргета:Чтобы проверить все ли таргеты видны можно зайти в web-интерфейс прометея:
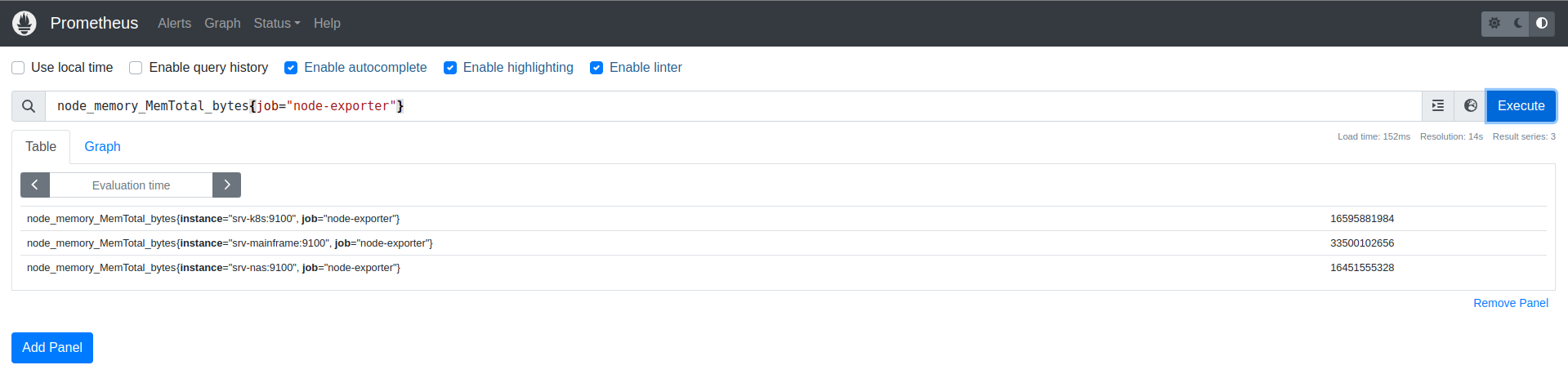
Для дебага запросов и проверки, что информация видна на всех узлах можно выполнить, например, запрос количества оперативной памяти:
Конфиг правила тревоги¶
groups:
- name: node_down
rules:
- alert: InstanceDown
expr: up == 0
for: 1m
labels:
user: test
annotations:
summary: "Instance {{ $labels.instance }} down"
description: "{{ $labels.instance }} of job {{ $labels.job }} has been down for more than 1 minutes."
Настройка Alertmanager¶
Конфиг alertmanager¶
Аналогично создадим директорию /docker/conf/alertmanager и положим конфиг:
global:
smtp_smarthost: 'smtp.mail.ru:465'
smtp_from: '[email protected]' # Адрес электронной почты
smtp_auth_username: '[email protected]' # Имя пользователя электронной почты, отправившего письмо, которое является вашим адресом электронной почты
smtp_auth_password: 'password' # Пароль электронной почты для отправки электронной почты
smtp_require_tls: false
route:
group_by: ['alertname']
group_wait: 10s
group_interval: 10s
repeat_interval: 10m
receiver: live-monitoring
receivers:
- name: 'live-monitoring'
email_configs:
- to: '[email protected]' # Адрес электронной почты
Запускаем наш стек мониторинга:
Настройка Grafana¶
Аналогична предыдущей настройки. Приведу несколько полезных дашбордов:
- Cadvisor exporter | 14282
- Node Exporter Full | 1860
- Docker Swarm Dashboard | 11939
- Docker and system monitoring (nodeexporter v1.3.1) | 16310
- Swarm Stack Monitoring | 7007
На этом всё! 
