▍Monitoring Stack¶

Настройка мониторинга на Prometheus + Cadvisor + Node Exporter + Grafana + Alertmanager¶
В данной инструкции будет показан быстрый способ поднять систему мониторинга с помощью docker-compose. Сам Prometheus будет отвечать за сбор данных, а Grafana за их отображение.
Экспортёры данных в Prometheus:
- Node Exporter, отвечает за сбор данных об оборудовании хоста и операционной системе.
- cAdvisor, отвечает за сбор данных docker контейнеров.
- Alertmanager, отвечает за оповещения.
Compose для нашего стека мониторинга¶
version: '3.3'
services:
grafana:
image: grafana/grafana-oss:latest
container_name: grafana
restart: always
volumes:
- $DIR_DATA/grafana:/var/lib/grafana
labels:
- "traefik.enable=true"
- "traefik.http.routers.grafana.rule=Host(`grafana.example.ru`)"
- "traefik.http.routers.grafana.entrypoints=https"
- "traefik.http.routers.grafana.tls=true"
- "traefik.http.services.grafana.loadbalancer.server.port=3000"
- "traefik.http.routers.grafana.middlewares=WhitelistHome"
- "com.centurylinklabs.watchtower.enable=true"
prometheus:
image: prom/prometheus
restart: always
container_name: prometheus
command:
- '--config.file=/etc/prometheus/prometheus.yml'
- '--storage.tsdb.path=/prometheus'
- '--web.console.libraries=/usr/share/prometheus/console_libraries'
- '--web.console.templates=/usr/share/prometheus/consoles'
ports:
- "9090:9090"
depends_on:
- cadvisor
volumes:
- $DIR_CONF/prometheus:/etc/prometheus
- $DIR_DATA/prometheus:/prometheus
labels:
- "com.centurylinklabs.watchtower.enable=true"
node:
image: prom/node-exporter
restart: always
container_name: node
ports:
- "9100:9100"
volumes:
- /proc:/host/proc:ro
- /sys:/host/sys:ro
- /:/rootfs:ro
- /:/host:ro,rslave
command:
- '--path.rootfs=/host'
- '--path.procfs=/host/proc'
- '--path.sysfs=/host/sys'
- --collector.filesystem.ignored-mount-points
- "^/(sys|proc|dev|host|etc|rootfs/var/lib/docker/containers|rootfs/var/lib/docker/overlay2|rootfs/run/docker/netns|rootfs/var/lib/docker/aufs)($$|/)"
alertmanager:
image: prom/alertmanager
restart: always
container_name: alertmanager
command:
- '--config.file=/etc/alertmanager/alertmanager.yml'
- '--storage.path=/alertmanager'
ports:
- "9093:9093"
volumes:
- $DIR_CONF/alertmanager:/etc/alertmanager
cadvisor:
image: gcr.io/cadvisor/cadvisor
restart: always
container_name: cadvisor
devices:
- "/dev/kmsg:/dev/kmsg"
ports:
- "8080:8080"
volumes:
- /:/rootfs:ro
- /var/run:/var/run:rw
- /sys:/sys:ro
- /var/lib/docker/:/var/lib/docker:ro
- /dev/disk/:/dev/disk:ro
Настройка Prometheus¶
Создадим директорию /srv/docker/conf/prometheus в которой добавим следующие файлы:
Конфиг prometheus¶
# my global config
global:
scrape_interval: 15s # Set the scrape interval to every 15 seconds. Default is every 1 minute.
evaluation_interval: 15s # Evaluate rules every 15 seconds. The default is every 1 minute.
# scrape_timeout is set to the global default (10s).
# Alertmanager configuration
alerting:
alertmanagers:
- static_configs:
- targets: ['192.168.11.11:9093']
# - alertmanager:9093
# Load rules once and periodically evaluate them according to the global 'evaluation_interval'.
rule_files:
- "node_down.yml"
# - "first_rules.yml"
# - "second_rules.yml"
# A scrape configuration containing exactly one endpoint to scrape:
# Here it's Prometheus itself.
scrape_configs:
# The job name is added as a label `job=<job_name>` to any timeseries scraped from this config.
- job_name: 'prometheus'
static_configs:
- targets: ['192.168.11.11:9090']
- job_name: 'cadvisor'
static_configs:
- targets: ['192.168.11.11:8080']
- job_name: 'node'
scrape_interval: 8s
static_configs:
- targets: ['192.168.11.11:9100']
Конфиг правила тревоги¶
groups:
- name: node_down
rules:
- alert: InstanceDown
expr: up == 0
for: 1m
labels:
user: test
annotations:
summary: "Instance {{ $labels.instance }} down"
description: "{{ $labels.instance }} of job {{ $labels.job }} has been down for more than 1 minutes."
Полезные команды¶
Удалить данные старого хоста
Добавляем ключ --web.enable-admin-api в параметры запуска, чтобы получилось:
prometheus:
image: prom/prometheus
restart: always
container_name: prometheus
command:
- '--config.file=/etc/prometheus/prometheus.yml'
- '--storage.tsdb.path=/prometheus'
- '--web.console.libraries=/usr/share/prometheus/console_libraries'
- '--web.console.templates=/usr/share/prometheus/consoles'
- '--web.enable-admin-api'
...
curl -X POST -g 'http://172.21.0.13:9090/api/v1/admin/tsdb/delete_series?match[]={instance="node:9100"}'
Настройка Alertmanager¶
Конфиг alertmanager¶
Аналогично создадим директорию /srv/docker/conf/alertmanager и положим конфиг:
global:
smtp_smarthost: 'smtp.mail.ru:465'
smtp_from: '[email protected]' # Адрес электронной почты
smtp_auth_username: '[email protected]' # Имя пользователя электронной почты, отправившего письмо, которое является вашим адресом электронной почты
smtp_auth_password: 'password' # Пароль электронной почты для отправки электронной почты
smtp_require_tls: false
route:
group_by: ['alertname']
group_wait: 10s
group_interval: 10s
repeat_interval: 10m
receiver: live-monitoring
receivers:
- name: 'live-monitoring'
email_configs:
- to: '[email protected]' # Адрес электронной почты
Запускаем наш docker-compose up -d.
Для проверки отправим тестовое письмо, выполнив следующую команду:
$ curl -H 'Content-Type: application/json' -d '[{"labels":{"alertname":"myalert"}}]' http://192.168.11.11:9093/api/v1/alerts
{"status":"success"}
Настройка Grafana¶
Необходимо добавить источник данных Prometheus:
Указываем адрес нашего Prometheus:
Теперь осталось добавить дашборды для мониторинга с node exporter и cAdvisor. Для этого уже есть готовые варианты. Выбираем Import:
Вводим номер 1860 и нажимаем на Load. Grafana подгрузит дашборд из своего репозитория, далее в разделе Prometheus указываем наш источник данных и кликаем по Import.
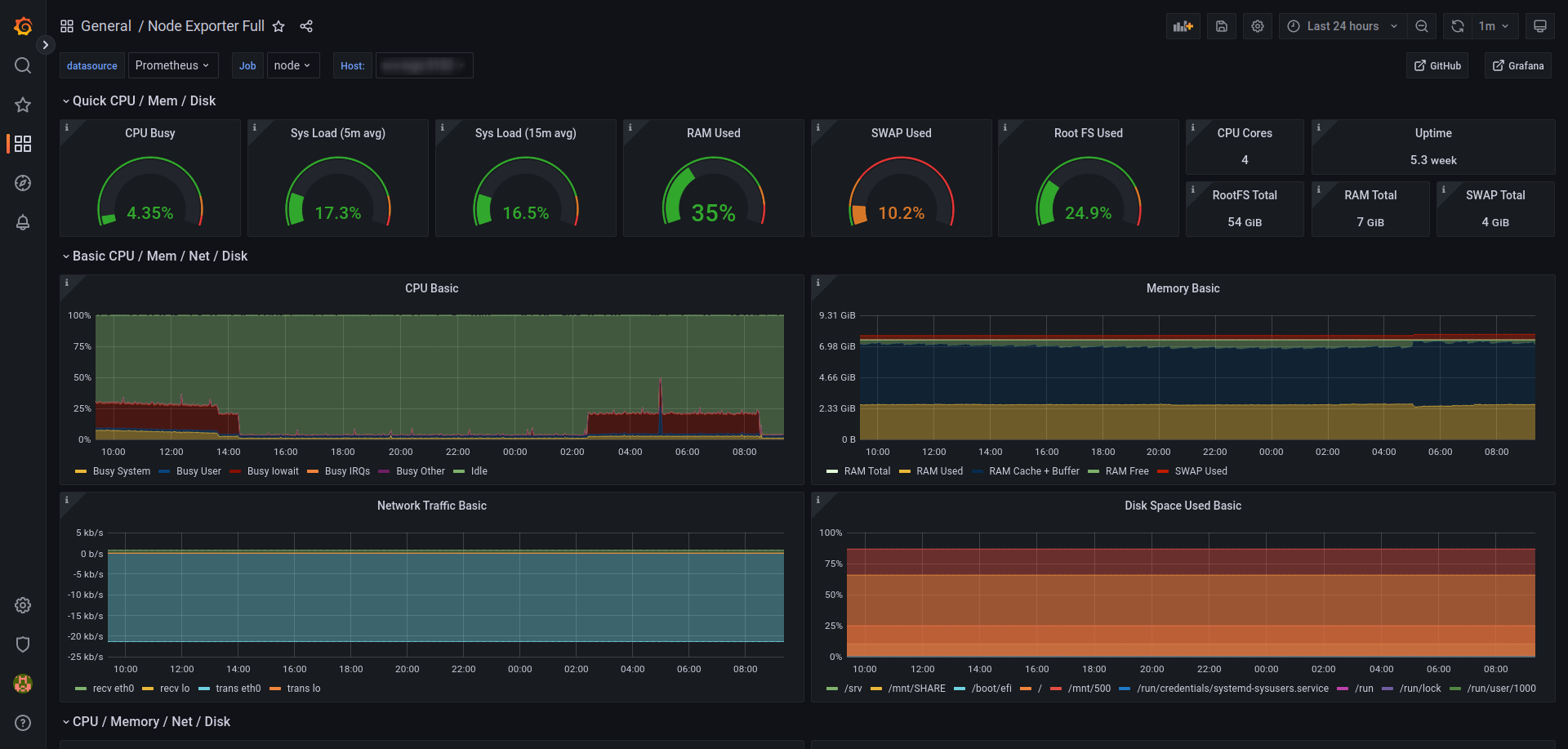
Аналогично добавим дашборд для данных cAdvisor, его номер - 14282.
Готово! 😎🤘